Production-Grade Semantic Routing: A CTO’s Guide to Cutting AI Costs Up to 60%

If you’re a CTO or Platform Engineer scaling GenAI, this is a practical architecture pattern you can implement.
The Reality: We’ve reviewed production GenAI architectures (both from internal engagements and public engineering write-ups) across support, search, and internal copilots.
The Pattern: Most teams are stuck in the “Demo Trap.” Their apps work perfectly with frontier models, but unit economics collapse at scale.
The Mistake: Treating every user query as a Tier-3 reasoning workload.
Here is the architectural blueprint for fixing your AI unit economics.
This isn’t just a cost problem, it’s an Architecture Problem
Picture this: Your team ships a new AI agent. In the demo, running on GPT-4, it’s magic. Stakeholders are thrilled. But in production, users hit the endpoint 50,000 times a day for simple queries like “reset my password” or “summarize this paragraph.”
The result: Your AI infrastructure bill scales linearly with user growth, often faster than your revenue.
For the last 30 years, engineering management was deterministic (If X, then Y). In the GenAI era, you are managing probabilistic systems.
If you hardcode model calls in your application layer, you are effectively burning cash. You need a control plan,e an AI Gateway that sits between your product and the models to make intelligent, dynamic decisions.
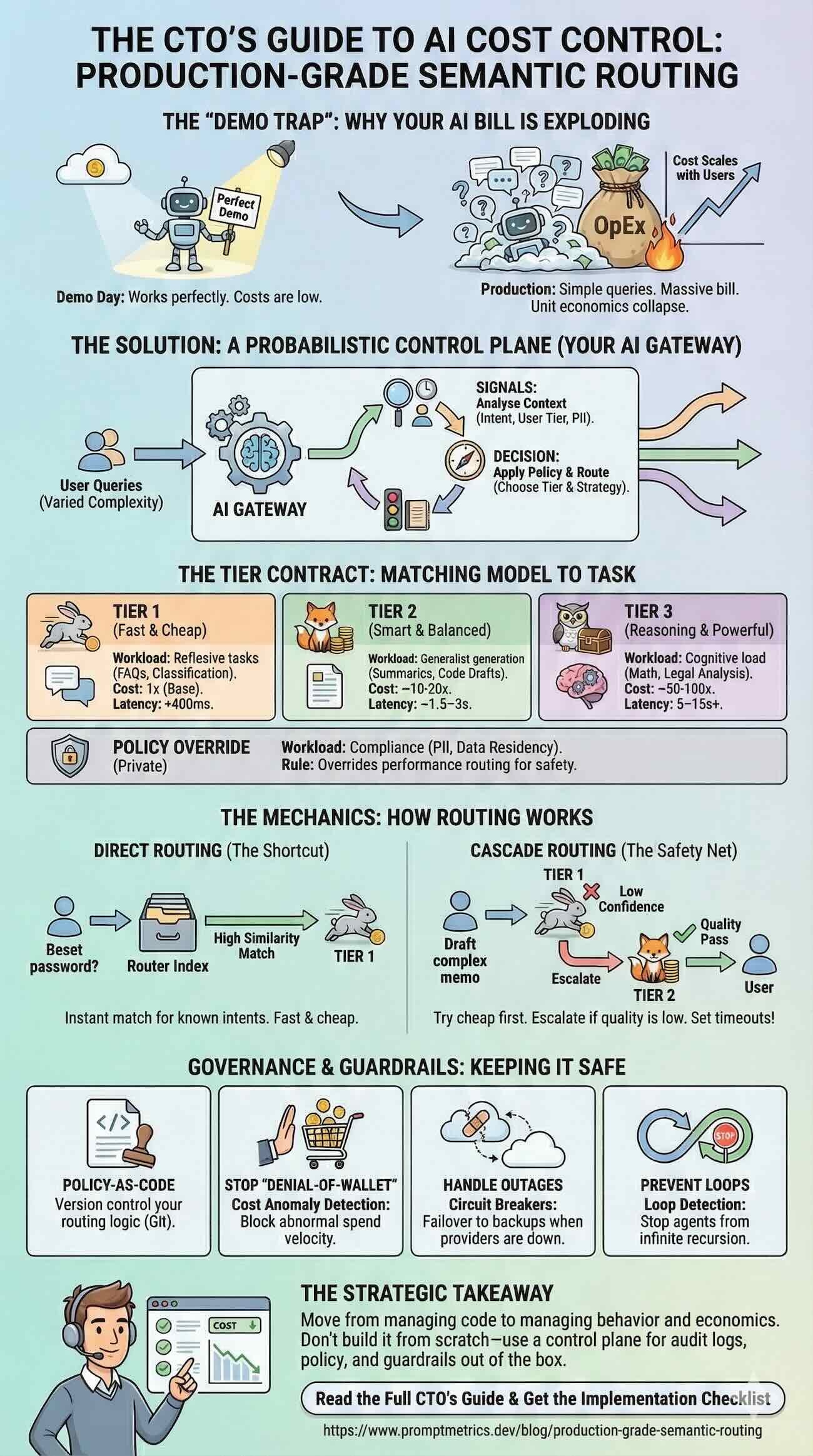
The Framework: Building a Probabilistic Control Plane
To break the linear cost curve, you must stop treating all queries as equal. Here is the 4-part architecture for a production-grade routing system.
1. The Operational Contract (The Tiers)
You need to architect your gateway around distinct performance tiers, not just random models. Note that tiers should map to multiple providers per tier to avoid single-vendor fragility.
(Costs vary by provider, context length, and whether you self-host vs. use hosted APIs, but the tier ordering and rough ratios generally look like this:)
Tier 1 (Fast): Reflexive tasks (FAQs, classification). Cost: 1x. Latency (P95 target): <400ms.
Tier 2 (Smart): Generalist generation (summaries, code drafts). Cost: ~10–20x. Latency (P95 target): ~1.5–3s.
Tier 3 (Reasoning): Cognitive load (math, legal analysis). Cost: ~50–100x (order-of-magnitude; token-length dominates). Latency (P95 target): 5–15s+.
Policy Override: Compliance-mandated routing (e.g., EU residency requirements).
The Goal: Push maximum volume to Tier 1 without violating your quality SLOs.
2. The Mechanics (Direct vs. Cascading)
Production routing requires two patterns:
Direct Routing: Instant intent matching via vector similarity (e.g., matching a FAQ). Fast and cheap.
Cascade Routing: The “safety net.” Try Tier 1 first. If confidence is low (e.g., schema fails, entropy spikes, or a verifier score drops), escalate to Tier 2.
Crucial: The hard part isn’t choosing a ti; it’s building reliable quality estimators, so cascades don’t leak cost.
Acceptance Criteria: Define explicit gates for Tier-1 success (schema-valid, non-refusal, minimum completeness, verifier score threshold); otherwise, escalate.
Guardrail: Cap cascade depth (e.g., max one escalation) and enforce per-tier timeouts to prevent P99 blowups.
3. Evaluation (Golden Sets & Shadow Routing)
You cannot deploy a router based on” vibes.” If a router can’t pass a Golden Set (historical logs with ideal tier labels) and a Shadow Routing evaluation (logging decisions without acting on them), it’s not production-ready.
4. Governance as Code
In a multi-team enterprise, you cannot rely on developers to implement safety checks. You need centralized guardrails:
Circuit Breakers: Detect unhealthy providers and remove them from routing; fail over (or hedge) to backups.
Smart Cost Anomaly Detection (MAD): To catch abnormal spend velocity.
Loop Detection: To stop agent/tool recursion before it drains your wallet.
Security Note: Routers can be gamed to force Tier-3 selection (cost amplification). Mitigate with Tier-3 rate limits, classifier agreement, and monitoring for universal-trigger patterns.
Why This Matters Now
These aren’t theoretical concerns. Semantic Routing is the difference between a toy prototype and a profitable business.
We are seeing mature engineering organizations cut costs by up to 60% (when most traffic is Tier-1 eligible and cascades are bounded) while actually improving perceived latency by routing simple tasks to faster models.
The complication? Building this infrastructure yourself, training classifiers, managing vector indices, and creating policy engines turns your best product engineers into infrastructure maintainers.
Get the Full Architecture Breakdown
We’ve written a comprehensive technical guide that breaks down the exact pseudocode, tier contracts, and evaluation pipelines you need.
→ Read the Full Guide: Production-Grade Semantic Routing
It includes:
Production Pseudocode: The exact logic for cascading with bounded timeouts.
The “Tier Contract” Table: Detailed breakdown of latency targets and triggers.
Evaluation Strategy: How to use “Golden Sets” and “Routing Regret” to validate safety.
Operational Guardrails: Implementing circuit breakers, MAD, and hysteresis.
Deep dive (8 min read) • Includes Python snippets & Architecture Diagrams
One Question for You
I’m curious about your current routing maturity:
Static: We hardcode one model (e.g., GPT-4) for everything.
Manual: The user selects the mode (e.g., “Basic” vs “Advanced”).
Heuristic: We route based on prompt length or simple keywords.
Semantic: We use embeddings/classifiers to route dynamically.
Cascade: We try cheap-first and escalate on quality checks.
Drop your answer in the replies. I'm trying to gauge where the industry is on the “probabilistic” maturity curve.
Cheers,
Izzy - CTO at PromptMetrics
Building observability for the probabilistic enterprise.
P.S. If you’re building AI products in the EU and need to navigate the AI Act without slowing down, subscribe. I post deep dives on compliance, LLM observability, and engineering strategy.